目标
任务3:抓取下列5页商标的数据,并将出现频率最高的申请号填入答案中
https://match.yuanrenxue.com/match/3分析
在查看请求时注意到了一个奇怪的请求,没有响应结果,响应头中却有set-cookie,但是重新设置的这个与请求携带的又是一样的。
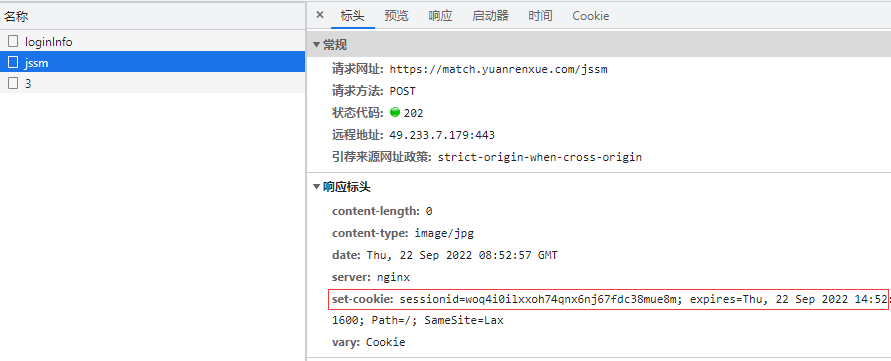
不知所以,就去重放了下请求,发现单独重放数据接口3返回的是一串script,但是按顺序放是可以正常拿到数据。
那么开始通过python模拟请求,但是发现不管是开始就携带cookie的requests请求,还是使用保持会话的session请求都不行。
既然这样,那只有对比一下两次请求有什么不一样。先刷新一下网页,然后使用Proxifier+charles全局代理后运行python
这里还有另一种方法,就是在代码中加入代理proxies = {"https":"127.0.0.1:8888"},直接代理到charles
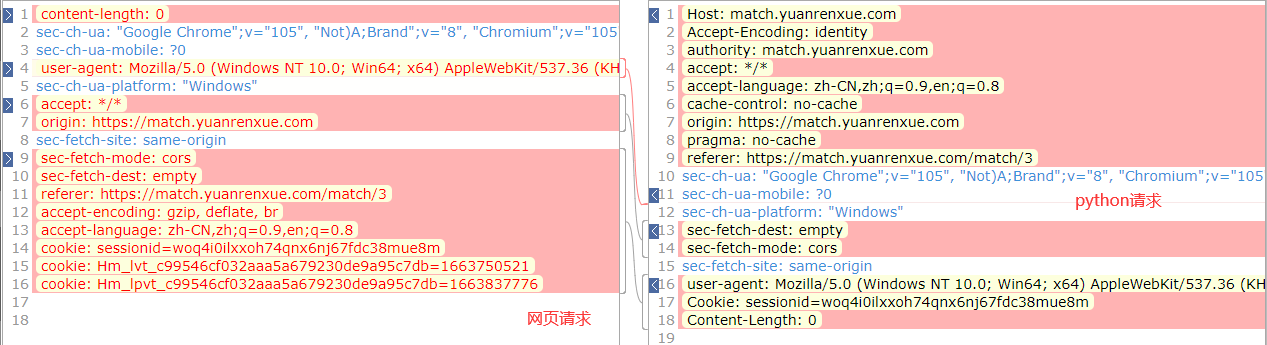
其实基本上差不太多,不过它能请求通自有它的道理,直接改成dict,丢到python中跑一下。
requests 库 的header排序是会被优先选择的,而在Session对象中不会。
那么用户应该考虑在 Session 对象上面设置默认 header,只要将 Session 设为一个定制的 OrderedDict 即可。
这样就会让它成为优选的次序。
这里应该是验证了顺序,所以需要用到session来请求。测试没有问题,请求成功了。
还原
# ==================================
# --*-- coding: utf-8 --*--
# @Time : 2022/9/22 16:47
# @Author : Gorkys
# @FileName: main.py
# @Software: PyCharm
# @describe: 猿人学第三题
# ==================================
import requests
headers = {
"content-length": '0',
"sec-ch-ua": '"Google Chrome";v="105", "Not)A;Brand";v="8", "Chromium";v="105"',
"sec-ch-ua-mobile": '?0',
"user-agent": "yuanrenxue.project",
"sec-ch-ua-platform": '"Windows"',
"accept": '*/*',
"origin": 'https://match.yuanrenxue.com',
"sec-fetch-site": 'same-origin',
"sec-fetch-mode": 'cors',
"sec-fetch-dest": 'empty',
"referer": 'https://match.yuanrenxue.com/match/3',
"accept-encoding": 'gzip, deflate, br',
"accept-language": 'zh-CN,zh;q=0.9,en;q=0.8',
'Cookie': 'sessionid=woq4i0ilxxoh74qnx6nj67fdc38mue8m; Hm_lvt_c99546cf032aaa5a679230de9a95c7db=1663750521; Hm_lpvt_c99546cf032aaa5a679230de9a95c7db=1663838829'
}
session = requests.session()
session.headers = headers
valueList = []
def getJssm():
url = "https://match.yuanrenxue.com/jssm"
session.post(url)
def getContent(page):
global valueList
response = session.get(f'https://match.yuanrenxue.com/api/match/3?page={page}').json()
data = response["data"]
print(response)
for i in range(len(data)):
valueList.append(data[i]["value"])
for i in range(5):
getJssm()
getContent(i + 1)
print(max(valueList, key=valueList.count))
# 8717